Step RL
Andrea Micheli, head of the PSO unit, won the ERC 2023 in the Starting Grant category, a prize dedicated to talented European researchers at the beginning of their career.
Abstract
Planning -- devising a strategy to achieve a desired objective -- is one of the basic forms of intelligence. Temporal planning studies the automated synthesis of strategies when time and temporal constraints matter: it is one of the most strategic fields of Artificial Intelligence, with applications in autonomous robotics, logistics, flexible production, and many other fields.
Historically, research on temporal planning has followed a general-purpose framework: a generic engine searches for the strategy by reasoning on the problem statement (i.e. the starting condition and the desired objective), as well as on a formal model of the domain (i.e. the possible actions). Despite substantial progress in the recent years, domain-independent temporal planning still suffers from scalability issues, and fails to deal with real-word problems. The alternative is to devise ad-hoc, domain-specific solutions that, although efficient, are costly to develop, rigid to maintain, and often inapplicable in non-nominal situations.
STEP-RL will study the foundations of a new approach to Temporal Planning that will be domain-independent and efficient at the same time. The idea is to adopt a framework based on Reinforcement Learning, where a domain-independent temporal planner is specialized with respect to the domain at hand. STEP-RL will continuously improve its ability to solve temporal planning problems by learning from experience, thus becoming increasingly efficient by means of self-adaptation.
STEP-RL will advance the state of the art in temporal planning beyond the "efficiency vs flexibility" dilemma, that we faced in many industrial projects of the PSO unit.
Motivation
There are two major motivating user objectives (UO) elicited from our experience on industrial projects:
-
UO1: Efficiency. TP must be able to solve real-world sized problems within reasonable time and computational resources; moreover, it must be able to optimize the plans according to user-defined metrics. We need to make planning faster and capable of dealing efficiently with complex optimization problems.
-
UO2: Adaptiveness. Temporal planners are rigid and rigorous in their methodic and systematic reasoning, giving formal guarantees and repeatability, but making it hard to cope with changing situations during executions. Users need the planning systems to (semi-)automatically adapt to evolving situations, such as permanent or transient changes of goals, faults during execution, and changes of preferences in the objective functions to optimize.
Concept
The key idea of the STEP-RL approach is to consider a "deployment phase" in which a temporal planner is specialized to serve the specific needs of UO1 and UO2. This is in sharp contrast with the classical aspiration of symbolic AI, which strives for general and domain-independent techniques: instead, I explicitly consider an automated phase for constructing specialized solvers.
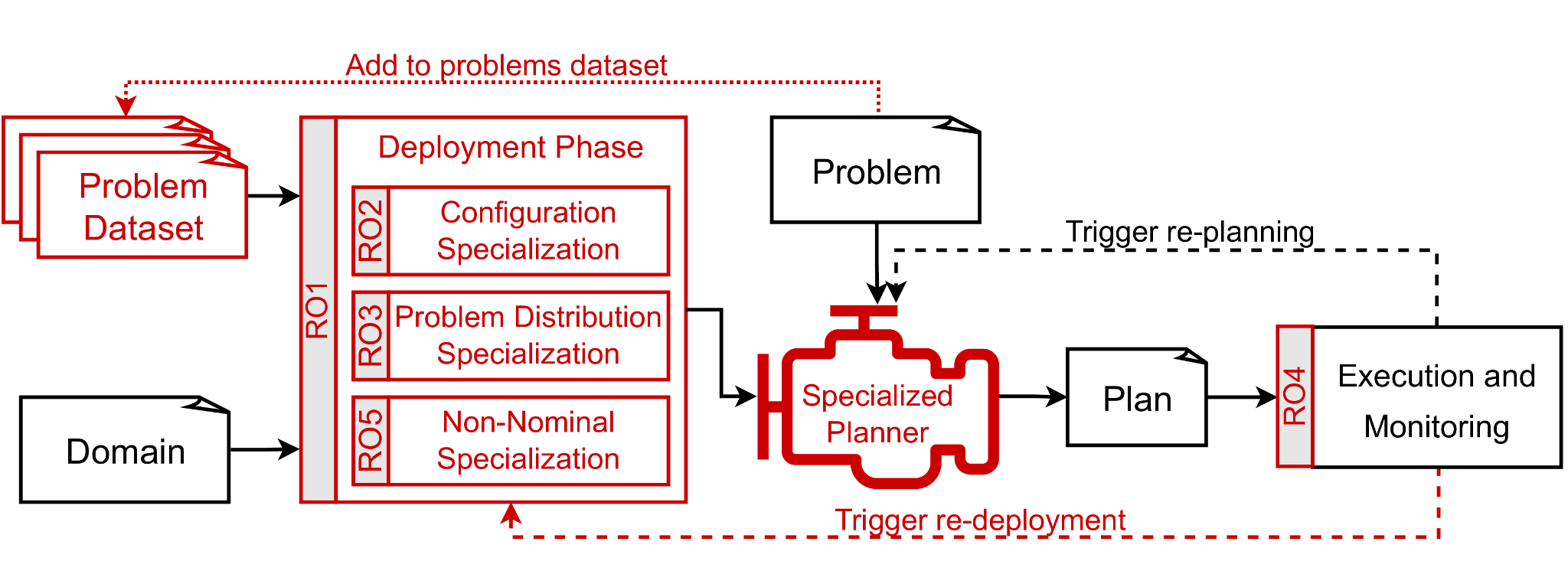
In a sentence, STEP-RL is a research program to specialize Temporal Planmning with RL. The project is organized around 5 research objectives, each opening a very significant research space since the related state of the art is quite limited.
-
RO1: Theoretical foundations. This research objective aims at laying down a comprehensive taxonomy of computational problems and to theoretically analyze the decidability, computational complexity, convergence and stability guarantees (or lack thereof).
-
RO2: Configuration specialization. Most planners offer a significant variety of parameters that heavily influence the performance and the characteristics of the generated plans. Moreover, different planning algorithms are available and are sometimes extremely different in their tradeoffs (e.g. consider state-space vs. plan-space algorithms). The aim of this research objective is to automatically determine the most promising configuration(s).
-
RO3: Problem-distribution specialization. A second level of specialization is the synthesis of artifacts that can guide the planning algorithms leveraging the experience acquired by means of RL on a set of example problems. The objective is to develop dedicated RL techniques aimed at the synthesis of guidance (in the form of e.g. domain knowledge, heuristics or ranking functions) aiding the planning algorithms. The scope of possibilities is vast and full of research challenges: How to represent the learned knowledge? How to define the reward function? How to adapt the learning architecture to the problems?
-
RO4: Monitoring. This research objective aims at the development of monitoring techniques to reliably understand if and when a re-deployment is needed and to signal abnormal situations that the specialized planner currently in use will not be able to handle.
-
RO5:Non-nominal specialization. One drawback of specialization (especially using learning techniques) is the risk of being unable to cope with unforeseen circumstances. This research objective aims at anticipating possible faults/discrepancies at deployment time to construct specializations dedicated at reacting to such faults. The monitoring techniques in RO4 will then be able to suggest the right specialization based on the observations; re-training can be used to enrich the collection of supported faults and discrepancies.
General Info
Start Date: 1 Jan 2024
End Date: 31 Dec 2028
Duration: 5 years
Funding: ERC Starting Grant
We are hiring!
We are looking for talented researchers and PhDs!
See jobs.fbk.eu for opportunities and fellowships concerning this project or contact the PI Andrea Micheli for more information.